
Blog page/post HTML not behaving as it should? Validate It!

Every now and again you’ll publish a blog post (or page) and find things amiss – paragraphs unevenly spaced, images bunched together (perhaps even out of order), title tags and/or lists badly aligned… Sound familiar? In situations like these, you’ve likely-as-not gone and somehow inadvertently messed up the HTML somewhere: perhaps there’s a closing (or opening) tag left unclosed (or unopened), or maybe you’ve got more (or less) tags than you should? Or maybe you’ve accidentally inserted a few tags where they were never intended to be placed? If you can spot the problem simply by examining your markup yourself then great – fix it and move on; but what if you can’t? …What if the post you’ve written is so long and complicated that the error refuses to make itself known… ?
Well, before you drive yourself around the bend looking over things one too many times… let’s take a look at an altogether easier way to see what might be wrong with your HTML…
Using the W3C Markup Validation Service:
Developed with the assistance of the Mozilla Foundation, the W3C Markup Validation Service is an extremely well-known HTML validator normally used to check the markup validity of Web documents in a range of different formats, such as HTML, XHTML, SMIL and MathML, etc – however, when WordPress HTML goes pear-shaped, you can also use this extremely-handy tool to find the errors… here’s how:
Step 1:
Create a text file (using say TextWrangler – or any other program used for editing plain text files, such as Sublime Text, Notepad++ or even TextEdit) and save it to your desktop as, say, “test.html”.
Step 2:
Paste the following into the top of the text file:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <title>Page Title</title> <meta http-equiv="Content-Type" content="text/html;charset=utf-8" > </head> <body>
(note that the above code is simply for the purposes of this particular validation methodology – i.e. not for general reference – and that we’re using HTML 4 Transitional here rather than HTML5 simply because, sadly, the W3C Validation Service doesn’t yet work very well with HTML5)
Followed by the entire content of your WordPress post (or page) – being careful to cut and paste from the WordPress Text Editor and NOT the WordPress Visual Editor (screenshot).
…followed by this:
</body> </html>
Step 3:
Save the file and head on over to the W3C Markup Validation Service. Select the “Validate by File Upload” tab (top of the page), upload your file and hit “Check”. You should then be presented with either a nice green message reading “This document was successfully checked as HTML 4.01 Transitional!” (in which case your problems probably lay elsewhere) or a not-so-nice red message reading “Error found while checking this document as HTML 4.01 Transitional!” – like so:
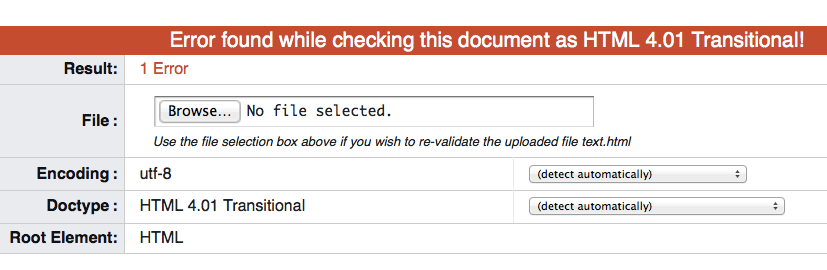
So, now we know there’s an error in the HTML, this could very well be the root of the problem… scroll down and you should be given the line number* on which there’s an HTML error (of which there may well be more than one of course).
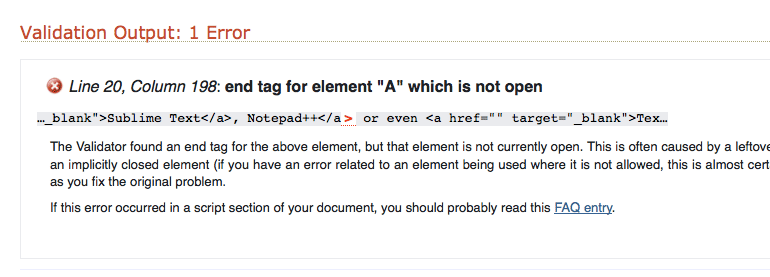
In the above example, we’re told there’s an error, on Line 20, Column 198 – created by the lack of an opening element “A” (a hyperlink) tag… ! Oops – how we managed to miss that howler I’ll never know… lol.
Seriously though, this can be a really great method for trying to find HTML mistakes in your posts/pages – one I usually end up having to use every couple of months or so… since that’s about the regularity with which I make a typo that, no matter how much I try, I somehow can’t seem to spot simply by looking over the code!
*note that, in my own experience, the error may or not be on this exact line: it may actually be one or two lines above or below the given line number.
Know of any other (perhaps better?) methods for spotting HTML goofs?



{kind=link}
All comments are held for moderation. We'll only publish comments that are on topic and adhere to our Commenting Policy.